
-
- Downloads
Update diagrams
Showing
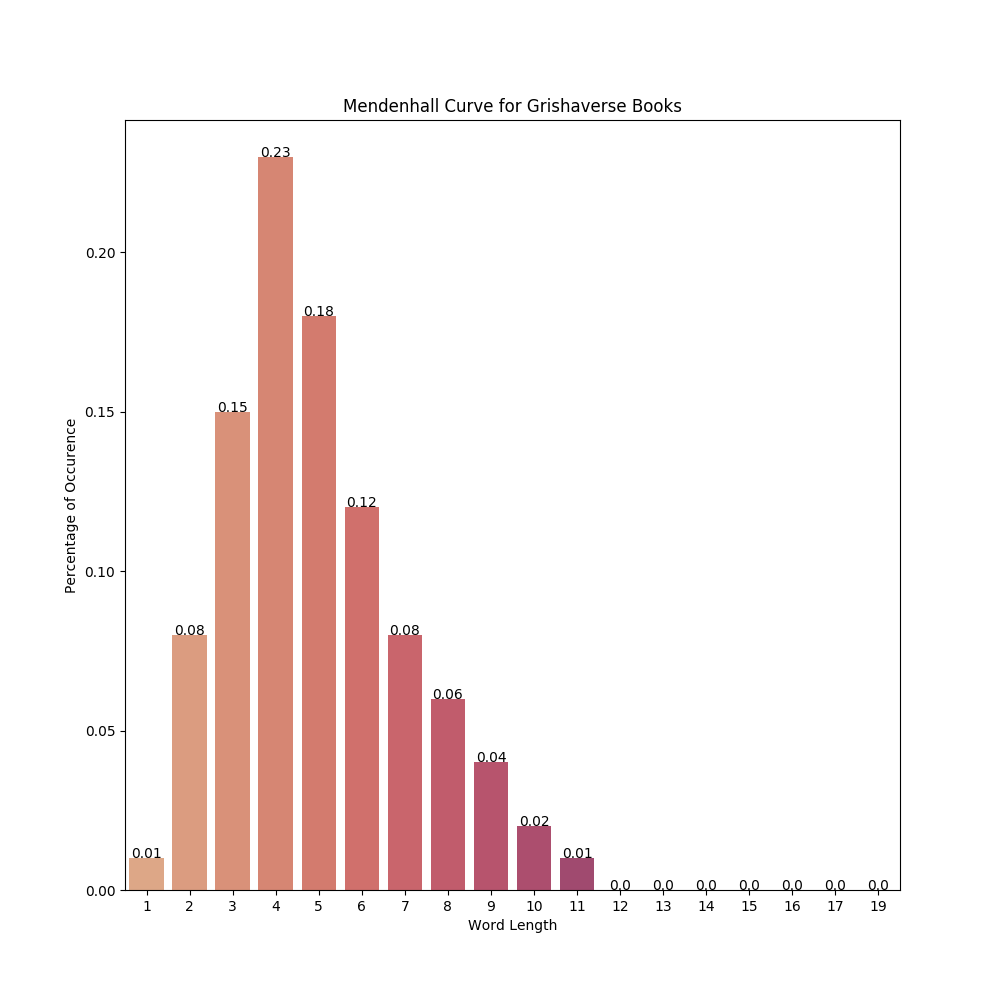
- grishaverse/freq_distribution/all_canon_token_len.png 0 additions, 0 deletionsgrishaverse/freq_distribution/all_canon_token_len.png
- stylometry_code.py 76 additions, 65 deletionsstylometry_code.py
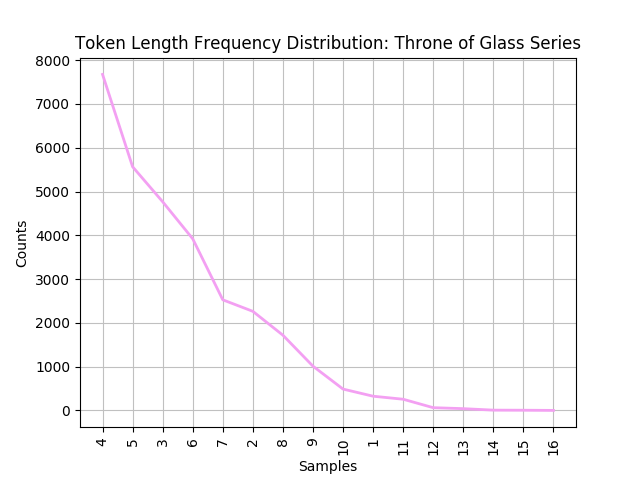
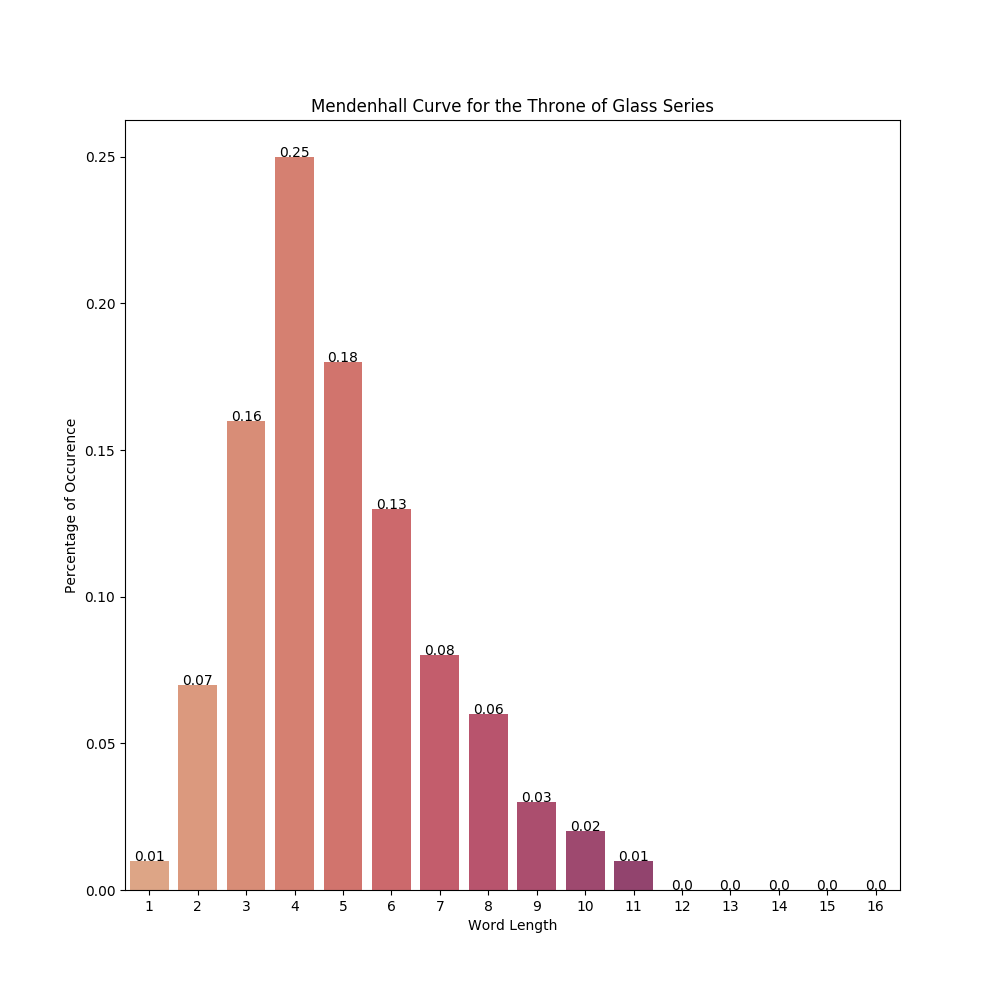
- throne_of_glass/freq_distribution/all_canon_token_len.png 0 additions, 0 deletionsthrone_of_glass/freq_distribution/all_canon_token_len.png
{kind=link}
32.8 KiB
{kind=link}
{kind=link}
| W: | H:
| W: | H: