
-
- Downloads
Add internal metrics
Showing
- data_overview/data_overview.png 0 additions, 0 deletionsdata_overview/data_overview.png
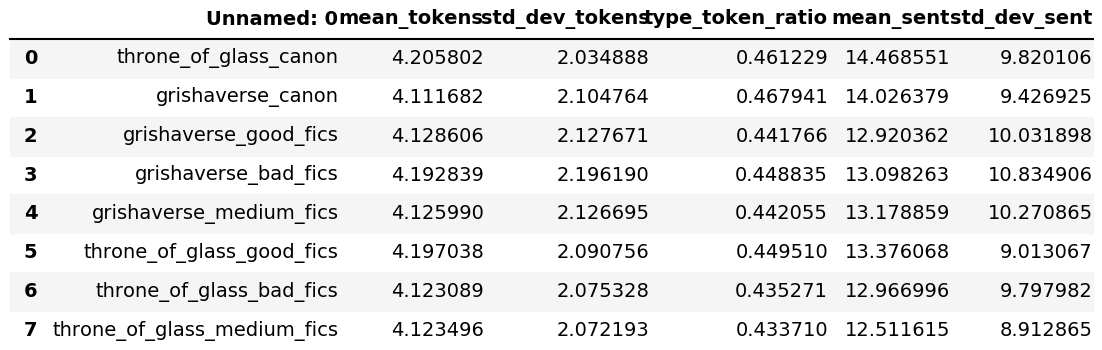
- data_overview/internal_fanfic_metrics.png 0 additions, 0 deletionsdata_overview/internal_fanfic_metrics.png
- data_overview/singular_and_then_averaged_over_grishaverse_fanfic_metrics.csv 3 additions, 0 deletions...lar_and_then_averaged_over_grishaverse_fanfic_metrics.csv
- data_visualisation.py 5 additions, 1 deletiondata_visualisation.py
- fanfic_internal_metrics.py 84 additions, 49 deletionsfanfic_internal_metrics.py
{kind=link}
{kind=link}
| W: | H:

| W: | H:
data_overview/internal_fanfic_metrics.png
0 → 100644
{kind=link}

52.9 KiB