
Clean up code and put it into classes
Showing
- clean_stylometry.py 579 additions, 0 deletionsclean_stylometry.py
- colour_code.py 21 additions, 0 deletionscolour_code.py
- fanfic_preprocessing.py 49 additions, 80 deletionsfanfic_preprocessing.py
- grishaverse/freq_distribution/fanfic_kudo_freq_dist.png 0 additions, 0 deletionsgrishaverse/freq_distribution/fanfic_kudo_freq_dist.png
- stylometry_code.py 6 additions, 27 deletionsstylometry_code.py
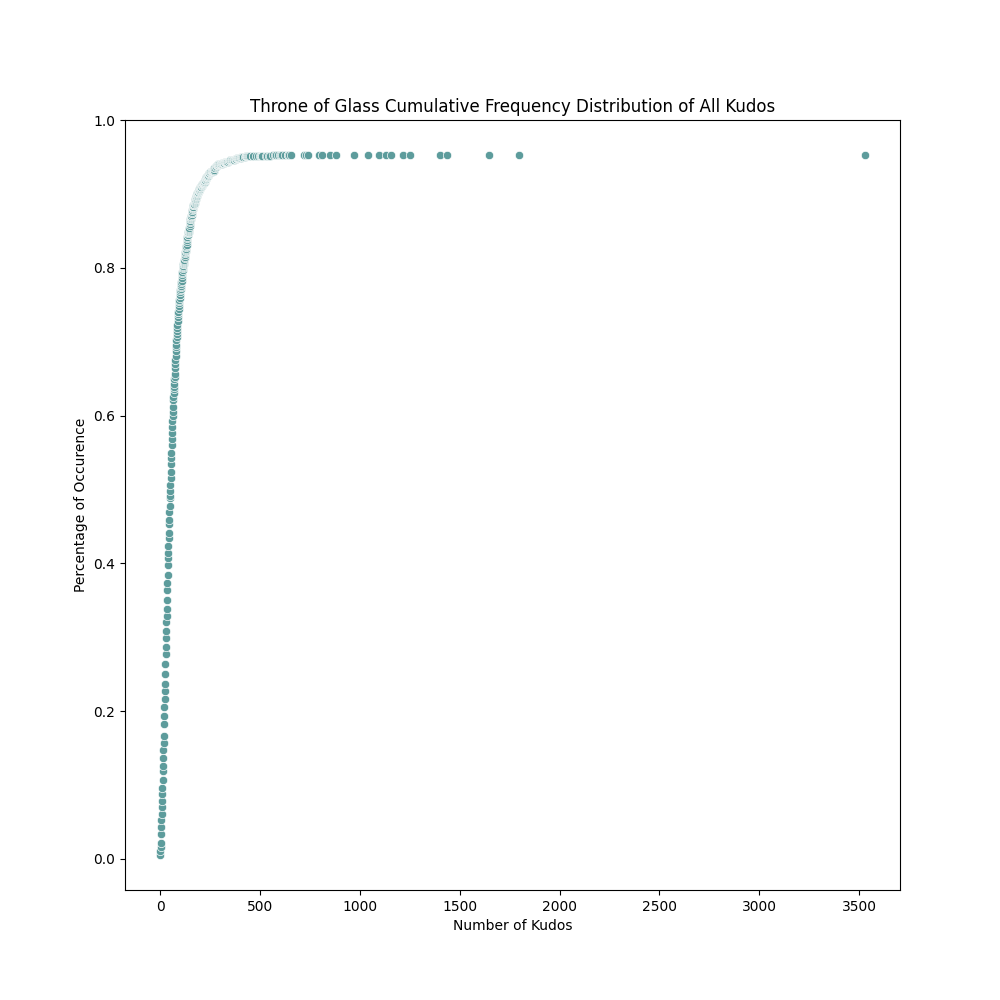
- throne_of_glass/freq_distribution/fanfic_kudo_freq_dist.png 0 additions, 0 deletionsthrone_of_glass/freq_distribution/fanfic_kudo_freq_dist.png
clean_stylometry.py
0 → 100644
colour_code.py
0 → 100644
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:
| W: | H: