
Software Projekt - Data Augmentation for Metonymy Resolution
Members of the project:
- Margareta Anna Kulscar kulscar@cl.uni-heidelberg.de
- Sandra Friebolin friebolin@cl.uni-heidelberg.de
- Mira Umlauf umlauf@cl.uni-heidelberg.de
Table of contents
-

-

-

-

-

-

-

-

-

This README gives a rough overview of the project. The full documentation and additional information can be found in the documents listed below.
-

-

-

-

A metonymy is the replacement of the actual expression by another one that is closely associated with it 1.
Metonymies use a contiguity relation between two domains.

-

- The term Brazil stands for a sports team of the country and is thus to be classified as a metonymy.
-

- This is a metonymy where the keyword Google stands for the owner of the company, but not for the literal sense of the term.
-
- Here, Brazil stands for the country and contains thus the literal meaning of the term.
-
- The term has literal meaning: Google refers to the company.
Metonymy resolution is about determining whether a potentially metonymic word is used metonymically in a particular context. In this project we focus on metonymic and literal readings for locations and organizations.

non-literal in this project. This is true of the following sentence, in which the term Nigeria prompts both a metonymic and a literal reading.
- "They arrived in Nigeria, hitherto a leading critic of [...]" 2
![]()
non-literal and literal for our binary classification task.
Data augmentation is the generation of synthetic training data for machine learning through transformations of existing data.
It is an important component for:
-

-
-
-
Consequently, it is a vital technique for evaluating the robustness of models, and improving the diversity and volume of training data to achieve better performance.
When selecting methods for our task, the main goal was to find a tradeoff between label preserving methods and diversifying our dataset. Since the language models BERT 3 and RoBERTa 4 have not been found to profit from very basic augmentation strategies (e.g. case changing of single characters or embedding replacements 5), we chose more innovative and challenging methods.
To be able to compare the influence of augmentations in different spaces, we select a method for data space and two methods for the feature space.
As a comparatively safe (= label preserving) data augmentation strategy, we selected backtranslation using the machine translation model Fairseq 6. Adapting the approach of Chen et al. 7 we use the pre-trained single models :
- [`transformer.wmt19.en-de.single_model`](https://huggingface.co/facebook/wmt19-en-de)
- [`transformer.wmt19.de-en.single_model`](https://huggingface.co/facebook/wmt19-de-en)-

-

-

temperature. This hyperparameter determines how creative the translation model becomes: highertemperatureleads to more linguistic variety, lowertemperatureto results closer to the original sentence. -

- Original: BMW and Nissan launch electric cars.
- EN - DE: BMW und Nissan bringen Elektroautos auf den Markt.
- DE - EN: BMW and Nissan are bringing electric cars to the market.

-
All paraphrases that did not contain the original (metonymic) target word or had syntactic variations were filtered out.
-
Those that contained the target word more than once were also filtered out.

Our method adopts the framework of the MixUp transformer proposed by Sun et al. 8. This approach involves interpolating the representation of two instances on the last hidden state of the transformer model (in our case, BERT-base-uncased).
To derive the interpolated hidden representation and corresponding label, we use the following formulas on the representation of two data samples:


Here,
We used a fixed

We use the same set fixed
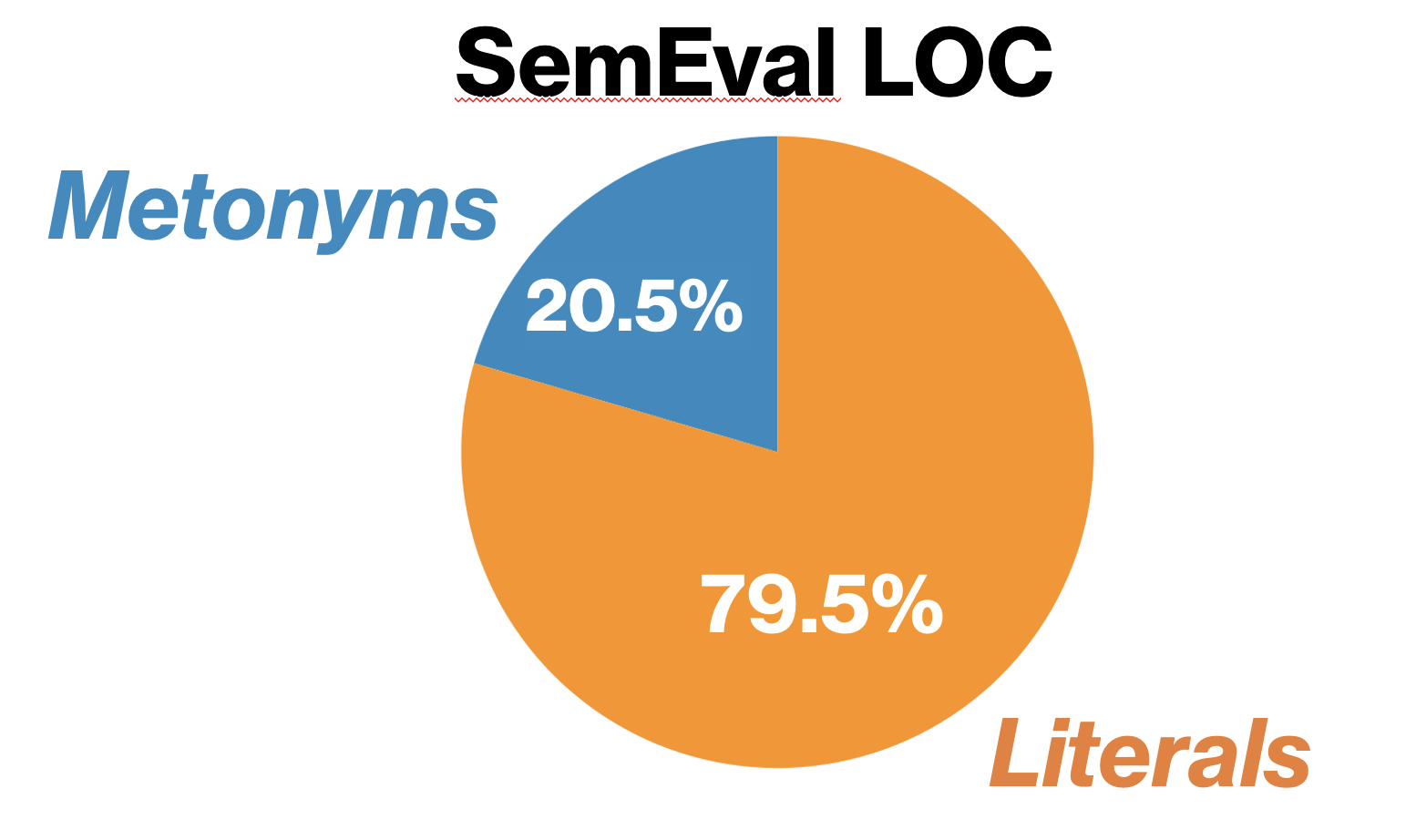
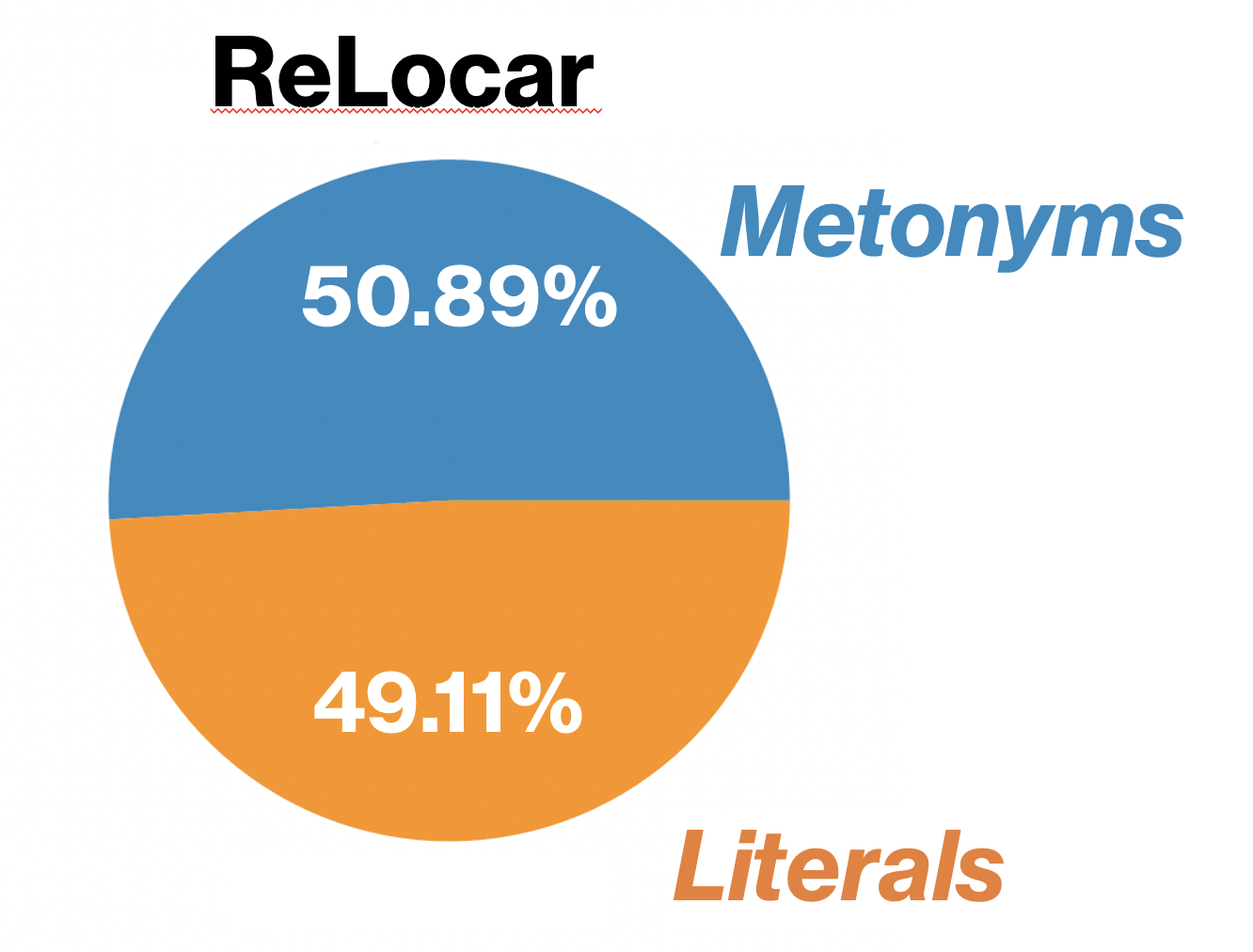
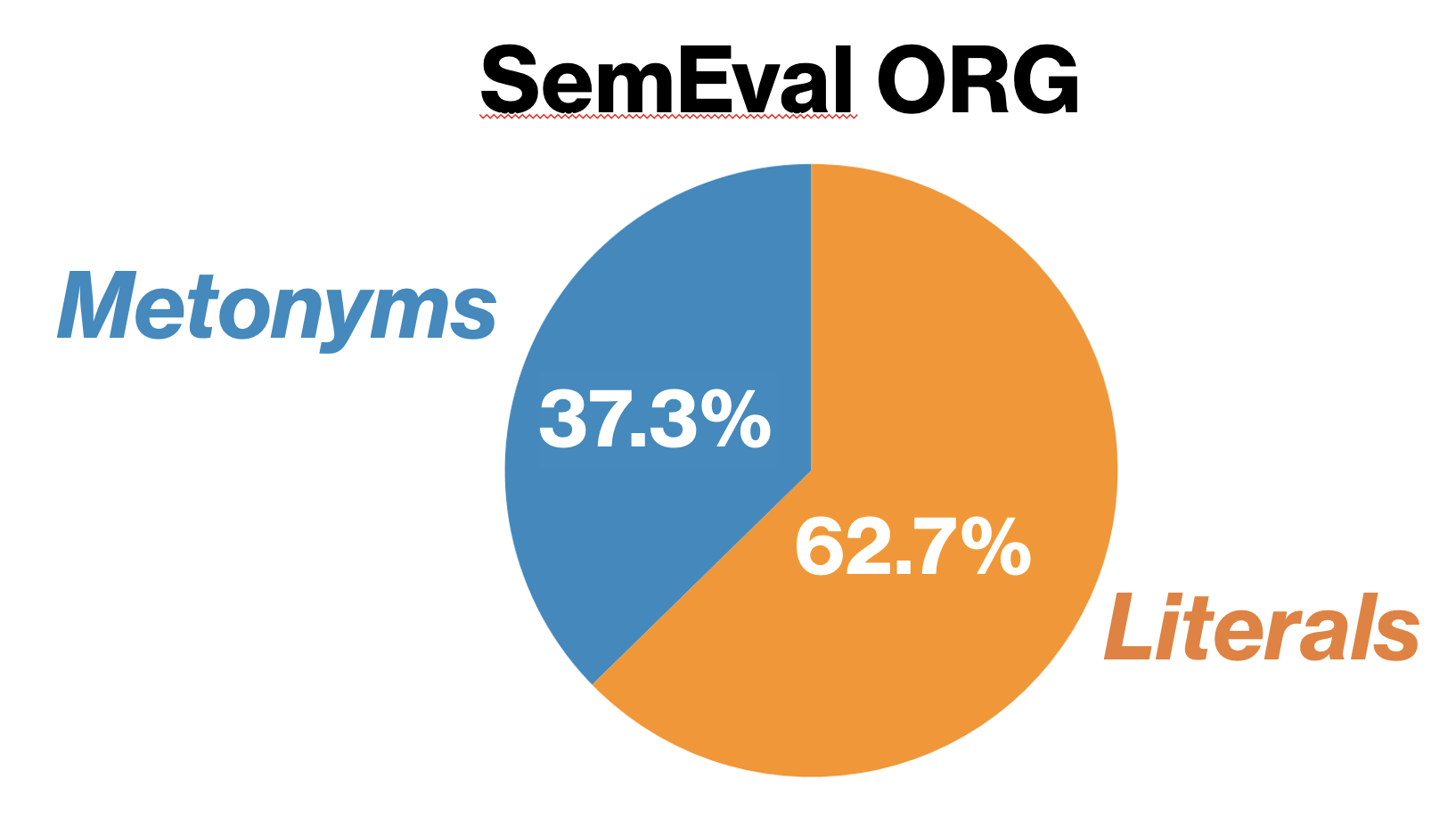
The datasets used in this project will be taken from Li et al.10 We confine ourselves to the following three:
| SemEval: Locations & SemEval: Companies & Organizations | ReLocar: Locations |
|---|---|
| 3800 sentences from the BNC corpus 2 | Wikipedia-baseddataset containing 2026 sentences 11 |
 |
 |
 |

{"sentence": ["The", "radiation", "doses", "received", "by", "workers", "in", "the", "UK", "are", "analysed."], "pos": [8, 9], "label": 0}

{"sentence": ["Finally,", "we", "examine", "the", "UK", "privatization", "programme", "in", "practice."], "pos": [4, 5], "label": 1}


Creating a virtual environment to ensure that dependencies between the different projects are separated is a recommended first step:
python3 -m venv mrda-venv
source mrda-venv/bin/activateInstall all necessary requirements next:
pip install -r requirements.txt[noch zu überlegen: evtl 2 requirements/envs für BT extra wegen torch version]

[welche argumente genau?]
./main.py <COMMAND> <ARGUMENTS>...For <COMMAND> you must enter one of the commands you find in the list below, where you can also find an overview about necessary <ARGUMENTS>.
| Command | Functionality | Arguments |
|---|---|---|
| General | ||
--architecture |
Defines which model is used. | Choose bert-base-uncased or roberta
|
--model_type |
How to initialize the Classification Model | Choose separate or one
|
--mixlayer |
Specify in which layer the interpolation takes place. Only select one layer at a time. |
Choose from {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11}
|
--tokenizer |
Which tokenizer to use when preprocessing the datasets. | Choose swp for our tokenizer, li for the tokenizer of Li et al. 10, or salami for the tokenizer used by another student project
|
-max/--max_length
|
Defines the maximum sequence length when tokenizing the sentences. |
 |
--train_loop |
Defines which train loop to use. | Choose swp for our train loop implementation and salami for the one of the salami student project. |
-e/--epochs
|
Number of epochs for training. | |
-lr/--learning_rate
|
Learning rate for training. | type=float |
-rs/--random_seed
|
Random seed for initialization of the model. | Default is 42 . |
-sd/--save_directory
|
This option specifies the destination directory for the output results of the run. | |
-msp/--model_save_path
|
This option specifies the destination directory for saving the model. | We recommend saving models in Code/saved_models. |
-tc/--tcontext
|
Whether or not to preprocess the training set with context. | |
--masking |
Whether or not to mask the target word. | |
-lambda/--lambda_value
|
Speficies the lambda value for interpolation of MixUp and TMix | Default is 0.4 , type=float
|
| MixUp specific | ||
-mixup/--mix_up
|
Whether or not to use MixUp. If yes, please specify lambda and -mixepoch
|
|
-mixepoch/--mixepoch
|
Specifies the epoch(s) in which to apply MixUp. | Default is None
|
| TMix specific | ||
--tmix |
Whether or not to use TMix. If yes, please specify -mixlayer and -lambda
|
|
| Datasets specific | ||
-t/"--train_dataset
|
Defines which dataset is chosen for training. | Choose any of the datasets from original_datasets, fused_datasets or paraphrases |
-v/--test_dataset
|
Defines which dataset is chosen for testing. | Choose from "semeval_test.txt", "companies_test.txt" or "relocar_test.txt" |
--imdb |
Whether or not to use the IMDB dataset. Note that this is only relevant for validating our TMix implementation. | |
-b/--batch_size
|
Defines the batch size for the training process. | Default is 32 . |
-tb/--test_batch_size
|
Specifies the batch size for the test process. | Default is 16 . |
extra: BT and inference
[ADD screenshot of demo?]
-
requirements.txt: All necessary modules to install. -

main.py: Our main code file which does ... -
Code: Here, you can find all code files for our different models and data augmentation methods. -

data: Find all datasets in this folder.-

backtranslations: Contains unfiltered generated paraphrases. -
fused_datasets: Contains original datasets fused with filtered paraphrases. Ready to be used for training the models. -
original_datasets: Semeval_loc, Semeval_org, Relocar in their original form. -
paraphrases: Contains only filtered paraphrases.
-
-
documentation: Contains our organizational data and visualizations.-
images: Contains all relevant visualizations. -
organization: Our research plan, presentation, final reports. -
results: Find tables of our results.
-
-
English Oxford Dictionary. "Metonymy" ↩
-
Markert, Katja & Nissim, Malvina. "SemEval-2007 task 08: Metonymy resolution at SemEval-2007." Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), 2007. ↩ ↩2
-
Devlin, Jacob, Chang, Ming-Wei, Lee, Kenton & Toutanova, Kristina. "BERT: pre-training of deep bidirectional transformers for language understanding." CoRR, 2018. ↩
-
Liu, Yinhan, Ott, Myle, Goyal, Naman, Du, Jingfei, Joshi, Mandar, Chen, Danqi, Levy, Omer, Lewis, Mike, Stoyanov, Veselin & Stoyanov, Veselin. "RoBERTa: A robustly optimized BERT pretraining approach." CoRR, 2019. ↩
-
Bayer, Markus, Kaufhold, Marc-André & Reuter, Christian. "A survey on data augmentation for text classification." CoRR, 2021. ↩
-
Ott, Myle, Edunov, Sergey, Baevski, Alexei, Fan, Angela, Gross, Sam, Ng, Nathan, Grangier, David & Auli, Michael. "fairseq: A fast, extensible toolkit for sequence modeling." Proceedings of NAACL-HLT 2019: Demonstrations, 2019. ↩
-
Chen, Jiaao, Wu, Yuwei & Yang, Diyi. "Semi-Supervised Models via Data Augmentation for Classifying Interactive Affective Responses." 2020. ↩
-
Sun, Lichao, Xia, Congying, Yin, Wenpeng, Liang, Tingting, Yu, Philip S. & He, Lifang. "Mixup-transformer: dynamic data augmentation for NLP tasks." 2020. ↩
-
Chen, Jiaao, Wu, Yuwei & Yang, Diyi. "MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification." 2020. ↩
-
Li, Haonan, Vasardani, Maria, Tomko, Martin & Baldwin, Timothy. "Target word masking for location metonymy resolution." Proceedings of the 28th International Conference on Computational Linguistics, December 2020. ↩ ↩2
-
Gritta, Milan, Pilehvar, Mohammad, Taher, Limsopatham, Nut & Collier, Nigel. "Vancouver welcomes you! minimalist location metonymy resolution." Proceedings of the 55th Annual Meeting of the Association for Computational, 2017. ↩