-
- Downloads
Merge branch 'master' of...
Merge branch 'master' of https://gitlab.cl.uni-heidelberg.de/friebolin/swp-data-augmentation-for-metonymy-resolution
No related branches found
No related tags found
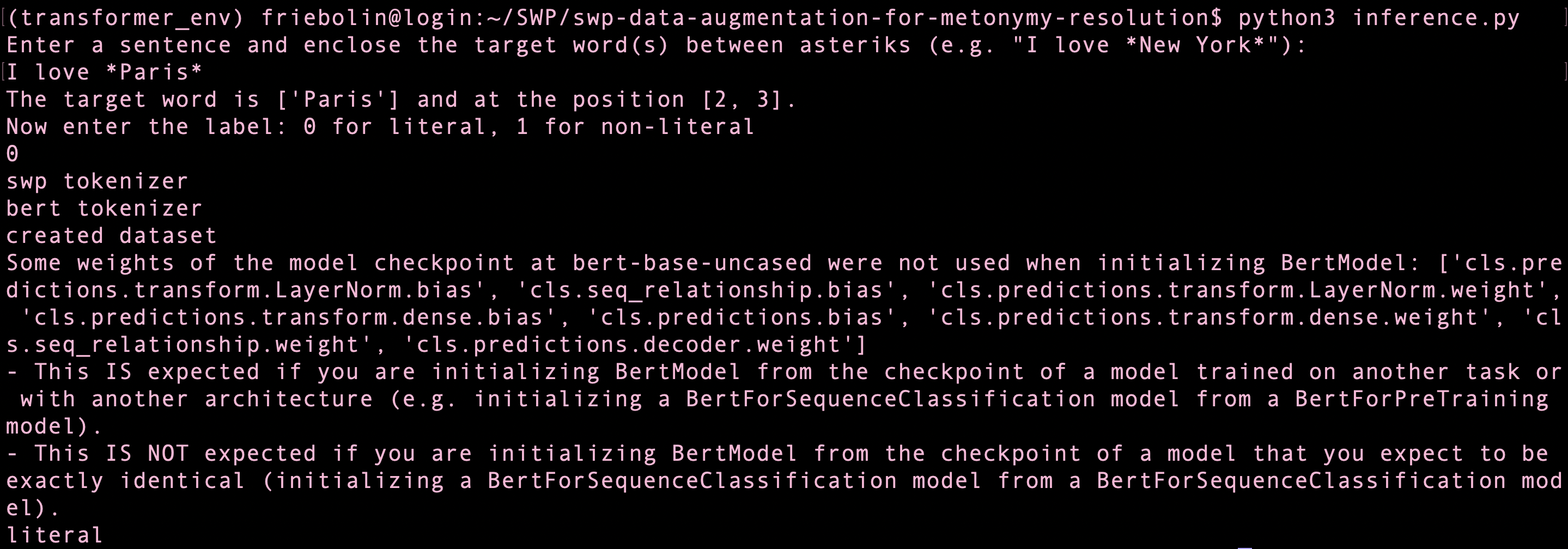
documentation/images/demo.png
0 → 100644
{kind=link}
1.13 MiB